在渗透测试的过程中,信息收集是非常重要的一步,收集到更完善的资产,可以让我们有着更广的攻击面,也更容易找到脆弱资产
前置知识
Google Hacking语法
谷歌语法就是利用搜索引擎在渗透测试过程搜索到特定页面的一种语法,可以利用其寻找子域名,寻找敏感信息等
基础符号
“xxx”:将要搜索的关键字用引号括起来 (表示完全匹配,即关键词不能分开,顺序也不能变)(关键字不区分大小写)
+:”xxx” +baidu.com
搜索xxx与baidu.com 相关的内容
-:”xxx” -baidu.com
搜索结果里面除去baidu.com 相关的内容
*通配符:必须在半角双引号内使用,用通配符代替关键词中无法确定的字词, * 前后需要加空格
逻辑与:and,A and B :检索同时含有A和B的内容
逻辑或:|,关键词(A|B):检索包含关键词带有A或B的内容
搜索参数
基本规则
基本语法:operator:search_term
布尔运算符和高级操作符可以结合使用,多个高级操作符可以在一次搜索中配合使用
以all开头的操作符在一次搜索中仅能使用一次,不能与其他高级操作符同时使用
基本操作符
site:指定域名,如:site:edu.cn搜索教育网站
inurl\allinurl:用于搜索包含的url关键词的网页,如:inurl:uploads 文件上传,搜索关于公司有关的网址中含有login的网页;allinurl:blog travel(可以匹配多个关键词,但不能使用别的高级操作符了,可以使用多个intitle,而不是allintitle)
intitle\allintitle:搜索网页标题中的关键字,如:
intitle:“index of /admin” robots.txt
intitle:“robots.txt”
index of:查找可浏览的服务器目录,常用于发现暴露的敏感文件
eg:
index of /admin#搜索开放目录列表中的 /admin 目录
"index of /" +passwd#在根目录下搜索 passwd 文件
"index of /config"#查找配置文件目录
intitle:”index of” /admin
intext\allintext:搜索网页正文中的关键字,如:intext:登陆/注册/用户名/密码
filetype:按指定文件类型即文件后缀名搜索,如:filetpye:php/asp/jsp
cache:已经删除的缓存网页,推荐组合使用
组合使用
可以通过这些基本操作符去寻找一些敏感文件泄露,寻找后台登录页等
filetype:sql "DROP TABLE" site:example.com#数据库备份文件
ext:log "error" "password"#日志文件
intitle:"admin login" inurl:/admin#后台登录页
————————————————————————
edusrc收集
site:xx.edu.cn filetype:pdf 身份证 学号 工号
site:google.com intext:身份证|sfz|学号|xh|登录|注册|管理|平台|验证码|账号|系统|手册|默认密码|初始密码|password|联系电话|操作手册|vpn|名单
site:google.com inurl:aspx|asp|php|jsp|do|.action|html
——————————————————————————
联合github
site:Github.com smtp @qq.com#邮件配置信息收集
site:Github.com root password#数据库信息收集
site:Github.com svn password#SVN信息收集
site:Github.com ftp ftppassword
网络空间搜索引擎语法
这里以FOFA为例
FOFA 是白帽汇推出的一款网络空间搜索引擎,它通过进行网络空间测绘,能够帮助研究人员或者企业迅速进行网络资产匹配,例如进行漏洞影响范围分析、应用分布统计、应用流行度等。
FOFA 搜索引擎检索到的内容主要是服务器,数据库,某个网站管理后台,路由器,交换机,公共IP的打印机,网络摄像头,门禁系统,Web服务 ……
常用语法
=:匹配,=””可查询不存在字段或者值为空的情况
==:完全匹配,==””时,可查询存在且值为空的情况
&&:与
||:或
!=:不匹配,!=””时,可查询值为空的情况
*=:模糊匹配,使用*或者?进行搜索,比如banner*="mys??"
():确认查询优先级,括号内容优先级最高
操作语法
ip:通过单一IPv4地址进行查询
port:通过端口号进行查询
domain:通过根域名进行查询
host:通过主机名进行查询
title:通过网站标题进行查询
body:通过HTML正文进行查询
icon_hash:通过网站图标的hash值进行查询
status_code:筛选服务状态为402的服务(网站)资产
icp:通过HTML正文包含的ICP备案号进行查询
cert:通过证书进行查询
FOFA也可以和谷歌语法一样,多个操作符组合起来进行查询,这样可以实现更多的功能,查询的结果也更准确
Github搜索语法
限定词
按照项目(仓库名称)搜索 in:name XXX 按照编程语言搜索 language:xxx 按照项目(仓库)描述搜索 in:description xxx 按照README文件描述搜索 in:readme xxx 按照star数限制搜索 stars:>n 按照fork数限制搜索 forks:>n 按照更新时间限制(时间晚于)搜索 pushed:>YYYY-MM-DD 按照某个人的某个项目限制搜索 repo:owner/name 搜索用户名下的所有项目(仓库)或某个项目(仓库)——用户名后加项目名称 org:username 搜索某个组织名下的项目(仓库) org:orgname 按照关注者数量搜索 node followers:>=10000 匹配有 10,000 或更多关注者提及文字 “node” 的仓库 eg:java in:name java,在java仓库中寻找
一些组合
in:name baidu #标题搜索含有关键字baidu
in:descripton baidu #仓库描述搜索含有关键字
in:readme baidu #Readme文件搜素含有关键字
license:apache-2.0 baidu #明确仓库的 LICENSE 搜索关键字
language:java baidu #在java语言的代码中搜索关键字
user:baidu in:name baidu #组合搜索,用户名baidu的标题含有baidu的等等
自动化工具:GitDorker
主域名收集
edu的主域名一般直接就是学校缩写.edu.cn
企业主域名收集
-
- 查企业股权树
- 查企业法人
- ICP备案:通过公司名去查备案号ICP
- 抓小程序包
子域名收集
通过子域名收集,可以扩大资产的范围,增加发现漏洞的概率
大部分情况下,主站的安全性可能相对较高,而一些不常用的子站或者上线不久的站点,安全方面的考虑可能并不周全,可能成为目标系统的脆弱点
通常情况下,同一组织采用相同应用搭建多个服务的可能性很大,以及补丁的情况也可能大致相同,因此,存在相同漏洞的概率非常大
利用fofa:使用domain,status_code 等
利用工具:oneforall,灯塔ARL,密探等
收集时可以通过多种方式对子域名进行收集,最后合并为一个文件,然后再对这个文件进行去重
测活
收集了资产之后,还要对以及收集的资产进行存活检测,识别那些资产是实际活跃并可访问的
httpx:
httpx -status-code -title -tech-detect -list domains.txt -mc 200 -o changedomains.txt
脚本
import requests
from requests.packages.urllib3.exceptions import InsecureRequestWarning
# 禁用SSL证书验证警告
requests.packages.urllib3.disable_warnings(InsecureRequestWarning)
print("开始子域名探活......")
print("存活的子域名:")
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:123.0) Gecko/20100101 Firefox/123.0"
}
# 读取子域名文件
with open('subdomain.txt', 'r') as file:
domains = [domain.strip() for domain in file.readlines()]
count = 0
processed_domains = set()
active_urls = [] # 存储所有Status为200的URL
for domain in domains:
if domain in processed_domains:
continue
processed_domains.add(domain)
# 尝试HTTP和HTTPS
for protocol in ['http', 'https']:
url = f"{protocol}://{domain}"
try:
response = requests.get(
url,
headers=headers,
timeout=15, # 增加超时时间
verify=False, # 忽略SSL证书错误
allow_redirects=True # 允许重定向
)
# 检查响应状态码和内容
if response.status_code == 200 and len(response.text) > 0:
count += 1
print(f"[+] {url} (Status: {response.status_code})")
active_urls.append(url) # 添加到活跃URL列表
break # 如果HTTP成功,不再尝试HTTPS
except requests.exceptions.SSLError:
print(f"[-] {url} (SSL证书错误)")
except requests.exceptions.ConnectionError:
print(f"[-] {url} (连接失败)")
except requests.exceptions.Timeout:
print(f"[-] {url} (请求超时)")
except requests.exceptions.RequestException as e:
print(f"[-] {url} (错误: {str(e)})")
# 将活跃URL写入文件
with open('active_urls.txt', 'w') as f:
for url in active_urls:
f.write(url + '\n')
print(f"\n探活结束,一共发现 {count} 个存活的子域名")
print(f"所有Status为200的URL已保存到 active_urls.txt")
漏洞扫描
使用xray,nuclei等扫描出可能存在漏洞的网站
通过这一步可以进一步测试出有用的资产
ip搜集
得到url后,单独提取其中的域名
可以利用Eeyes提取子域名的ip
Eeyes.exe -l subdomain.txt
然后可以根据c段提取其他ip
因为一些比较大的产业,很大可能会在卖服务器IP时是按c段买的,我们就可以利用这一点,说不定还可以获取不少隐蔽的站点等等。
提取c段的重复率,选择重复率高的c段进行检测
'''
# 打开原始的 IP 地址文件
with open('ip.txt', 'r') as file:
lines = file.readlines()
# 处理每个 IP 地址,转换为 C 段,并去除重复
c_segment_ips_set = set()
for line in lines:
ip = line.strip() # 移除每行末尾的换行符
base_ip = ip.rsplit('.', 1)[0] # 移除最后一个点号后的部分
c_segment_ip = f"{base_ip}.0/24"
c_segment_ips_set.add(c_segment_ip)
# 将转换后的 C 段 IP 地址写入到新文件
with open('c段.txt', 'w') as file:
for ip in c_segment_ips_set:
file.write(ip + '\n')
print("完成 IP 转换和去重,结果已保存到 'Modified_IP.txt'")
'''
from collections import Counter
# 打开原始的 IP 地址文件
with open('ip.txt', 'r') as file:
lines = file.readlines()
# 处理每个 IP 地址,转换为 C 段
c_segment_ips = []
for line in lines:
ip = line.strip() # 移除每行末尾的换行符
base_ip = ip.rsplit('.', 1)[0] # 获取 C 段(去除最后一个点号后的部分)
c_segment_ip = f"{base_ip}.0/24"
c_segment_ips.append(c_segment_ip)
# 统计每个 C 段的出现次数
c_segment_counts = Counter(c_segment_ips)
# 按出现次数从高到低排序
sorted_c_segments = sorted(c_segment_counts.items(), key=lambda item: item[1], reverse=True)
# 将排序结果写入到新文件 c段.txt
with open('c段.txt', 'w') as file:
for c_segment, count in sorted_c_segments:
file.write(f"{c_segment} 出现次数: {count}\n")
print("完成 C 段 IP 的统计、排序和保存,结果已保存到 'c段.txt'")
cdn绕过
CDN(内容分发网络)指的是一组分布在各个地区的服务器。这些服务器存储着数据的副本,因此。服务器可以根据哪些服务器与用户举例最近,来满足数据的请求。CDN提供快速服务,能降低高流量的影响。 通俗来讲,CDN就是用来加速访问网站的,通过在各地设置多个节点,用户访问时,就是在使用离用户最近的CDN节点进行访问。
CDN对渗透测试的影响
传统访问:用户访问域名–>解析服务器IP–>访问目标主机
普通CDN:用户访问域名–>CDN节点–>真实服务器IP–>访问目标主机
带WAF的CDN:用户访问域名–>CDN节点(WAF)–>真实服务器IP–>访问目标主机
所以在访问带CDN的网站时,获取的IP;并非网站的真实IP
识别
1.多地ping;如果出现多个IP即为启用了CDN服务
网站测速|网站速度测试|网速测试|电信|联通|网通|全国|监控|CDN|PING|DNS 一起测试|17CE.COM
2.nslookup进行检测,如果返回域名解析对应多个IP地址,则大概率使用了CDN
绕过方式
查询子域名
很多时候只会对主站或者流量较大的子站使用CDN服务,而还有部分子站是没有挂CDN的,而很多小站子站点又跟主站在同一台服务器或者同一个C段内,此时就可以通过查询子域名对应的 IP 来辅助查找网站的真实IP
全球ping
接口查询国外请求访问
Get Site IP – Find IP Address and location from any URL
fuckcdn
历史DNS解析记录
站点在使用CDN服务之前,它的真实IP地址可能被DNS服务器所记录到,此时我们就可以通过DNS历史记录找到目标真实IP
主动发送邮件
让对方服务器主动发邮件给你(注册、找回密码等功能)
网络空间引擎搜索法
输入title:“网站的title关键字”或者body:“网站的body特征”就可以找出fofa收录的有这些关键字的ip域名,很多时候能获取网站的真实ip
抓app包
有时候网站使用了CDN,但是其app可能没有使用,这时就可以通过抓取app的数据包有可能得出真实的IP地址
遗留文件及漏洞
遗留文件,如phpinfo页面泄露
漏洞探针:如:SSRF
指纹识别
通过主动或被动方式收集目标系统的特征信息,以识别其使用的操作系统,框架类型,开发语言,CDN,WAF类别等,可以更好的定位目标系统的技术特征, 为后续的攻击提供情报,可以针对目标系统寻找nday
cms指纹识别
cms是一个内容管理系统,大多数网站的内容都是通过cms来进行内容管理的
这些网站都是基于一系列开源的建站系统建立起来的,比如:利用discuz来建立论坛,wordpress来建立博客网站
如果在打开一个网站后,并且识别出了这个网站用的什么系统什么版本,就可以利用其的漏洞,可以利用一些简单的版权信息,网页标签查询,特定文件md5值来确定网站的cms系统
还可以利用kali自带的whatweb
whatweb -v 1nksy.cn
WAF指纹识别
一个Web应用防火墙,过滤HTTP/HTTPS的请求,用来识别恶意参数和恶意请求
SQL Injection (SQLi):阻止SQL注入
Cross Site Scripting (XSS):阻止跨站脚本攻击
Local File Inclusion (LFI):阻止利用本地文件包含漏洞进行攻击
Remote File Inclusione(RFI):阻止利用远程文件包含漏洞进行攻击
Remote Code Execution (RCE):阻止利用远程命令执行漏洞进行攻击
PHP Code Injectiod:阻止PHP代码注入
HTTP Protocol Violations:阻止违反HTTP协议的恶意访问
HTTPoxy:阻止利用远程代理感染漏洞进行攻击
Sshllshock:阻止利用Shellshock漏洞进行攻击
Session Fixation:阻止利用Session会话ID不变的漏洞进行攻击
Scanner Detection:阻止黑客扫描网站
Metadata/Error Leakages:阻止源代码/错误信息泄露
Project Honey Pot Blacklist:蜜罐项目黑名单
GeoIP Country Blocking:根据判断IP地址归属地来进行IP阻断
首先可以根据不同的拦截页面来确定不同的厂商
还可以通过如下思路识别: 额外的cookie; 任何响应或请求的附加标头; 响应内容(如果被阻止请求); 响应代码(如果被阻止请求); IP地址(云WAF); JS客户端模块(客户端WAF)
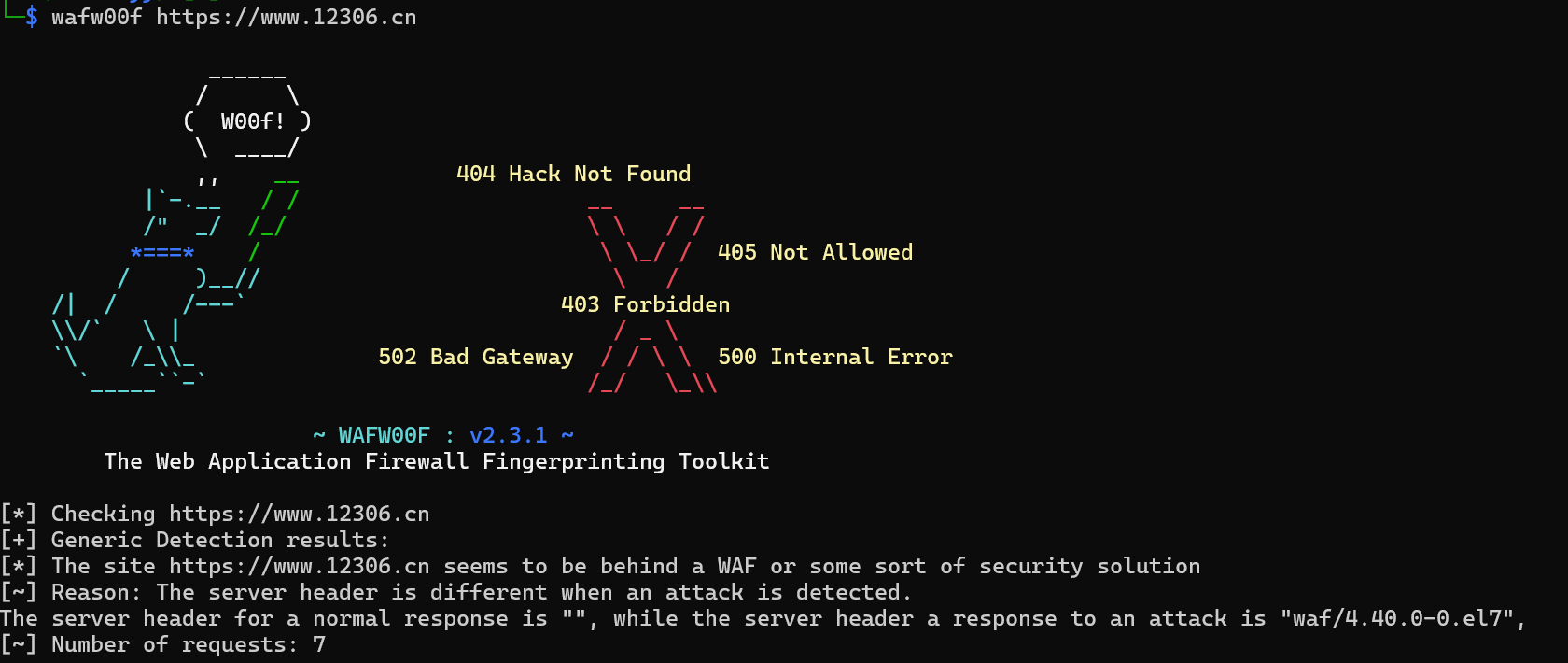
使用工具
kali自带的wafw00f
wafw00f 域名
使用nmap
nmap -p 80,443 --script=http-waf-detect www.12306.cn
nmap www.12306.cn --script=http-waf-detect.nse
脆弱资产:通过指纹特征识别出的已知漏洞或配置缺陷的组件,这些组件可能成为攻击者突破系统的入口。如:已知目标使用phpmyadmin,且版本为4.8.x,就可以直接利用其已知的本地文件包含漏洞
工具
浏览器插件:daydaypoc,wappalyzer
dddd:
指纹识别(不进行漏洞扫描):dddd.exe -t xxx.cn -npoc
其他
网页时光机
一个由互联网档案馆维护的在线服务,可以看见某一特定网站过去的样子。如果一个网站前期存在信息泄露,但后面将其泄露的页面删除后,这时就可以通过网页时光机查看其删除之前的敏感路径。
find something看接口和路由
接口(API):是前后端数据交互的通道。用于客户端和服务器之间的通信
路由:服务器将URL路径映射到处理逻辑的规则,决定用户访问时返回什么内容
一个浏览器插件,能爬取网站中的源码和JS文件,看是否存在未授权访问的API接口。

可以将路径复制,使用burp爆破,看是否存在未授权
网盘泄露
日常中我们基本都会使用网盘来分享资源,如百度,阿里等,分享时产生的链接也是会被某些平台给爬取收录的,就造成了网盘泄露,有的网站就会收录这些资源